Best Practices for Data Mapping in Salesforce Data 360
- sfmcstories
- Jan 18
- 4 min read
Data mapping in Salesforce Data Cloud is often underestimated because it happens early, quietly, and mostly out of sight. Yet it is precisely this early phase that determines whether identity resolution behaves predictably, whether unified profiles can be trusted, and whether downstream activation delivers value or confusion. This blog takes a deliberately deep, examining data mapping as a design discipline rather than a configuration task.

Data Mapping as a Foundational Design Decision
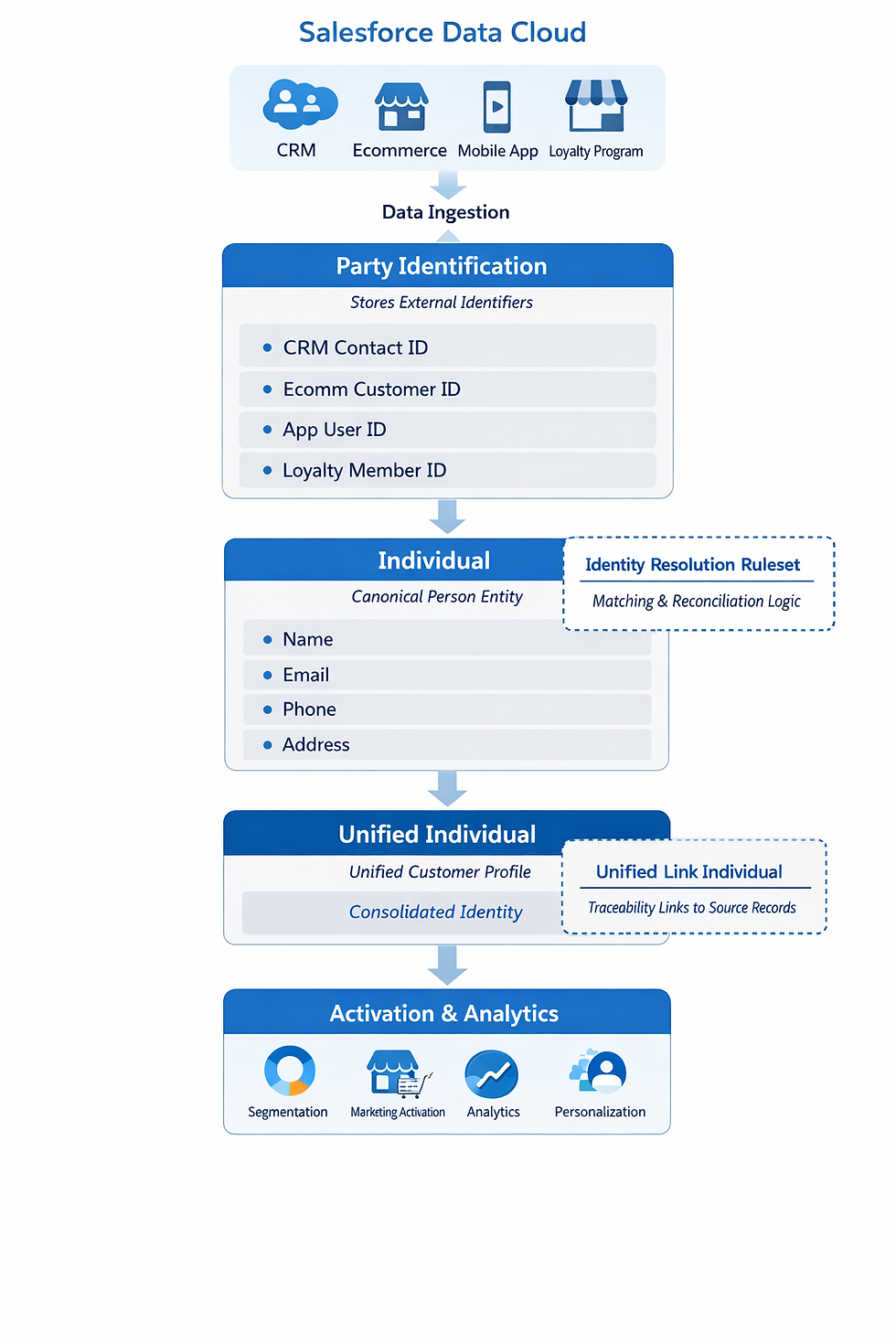
In Data Cloud, mapping is not merely a mechanical exercise of aligning source fields to target attributes. It is the point at which business meaning is translated into a customer-centric data model. Every decision made during mapping implicitly answers questions about identity, ownership, trust, and usage.
When mapping is treated as a technical checkbox, teams often discover problems only after unification or activation. At that stage, fixes become costly because identity graphs and unified profiles have already been constructed on shaky assumptions. Thoughtful mapping, by contrast, creates a stable substrate on which all Data Cloud capabilities depend.
Begin With Business Semantics, Not Schema
A common anti-pattern is to start mapping by opening the source system schema and working field by field. This approach optimizes for speed, not correctness. In practice, fields with identical names across systems often represent subtly different concepts. An “Email” field in CRM may represent a verified communication channel, while the same field in a marketing platform may simply reflect the last captured address.
Effective mapping begins by clarifying business semantics. Each attribute should have a clear definition, an understood owner, and an agreed purpose. Only once this semantic alignment exists should the technical mapping begin. This step may feel slow, but it prevents downstream misinterpretation and rework.
Choosing the Right Data Model Object Is a Strategic Act
Salesforce Data Cloud’s Standard DMOs encode years of platform design thinking. They reflect how Salesforce expects customer data to behave across identity resolution, segmentation, and activation. Ignoring these objects in favor of custom structures often introduces unnecessary friction.
A deep-dive mapping approach evaluates whether a standard DMO already captures the business meaning of the data. When it does, using it aligns the implementation with native platform behavior and future enhancements. Custom DMOs should be introduced only when the data truly represents a distinct business concept that cannot be modeled through extension or enrichment.
This decision has long-term consequences. Architects who choose wisely here reduce integration complexity, while those who default to custom structures often inherit avoidable maintenance burdens.
Identity Fields Demand Special Discipline
Not all fields influence Data Cloud equally. Identity-related attributes—such as email addresses, phone numbers, customer IDs, and loyalty identifiers—carry disproportionate weight because they directly affect unification outcomes.
Deep-dive mapping treats these fields as first-class citizens. Their formats, nullability, and consistency across systems must be validated early. Even minor inconsistencies, such as casing differences or mixed delimiters, can prevent intended matches or cause unintended ones.
Mapping identity fields without understanding how they will be used in identity resolution is one of the most common causes of incorrect unification.
Attribute Purpose Should Drive Mapping Decisions
Every mapped attribute should justify its existence. A structured deep dive asks not only where does this field come from, but also why does it belong in Data Cloud.
Some attributes exist to support identity resolution. Others enable segmentation, personalization, analytics, or compliance. When attributes are mapped without a clear downstream purpose, they add noise rather than value. Over time, this noise complicates governance and reduces trust in the unified profile.
Disciplined teams resist the temptation to “map everything” and instead focus on mapping what will be used, understood, and maintained.
Resist the Transactional Mindset
Source systems are designed for operational efficiency, not customer understanding. CRM systems optimize for sales processes, marketing platforms for campaign execution, and service systems for case management. Data Cloud, however, is optimized for customer-centric analysis and activation.
A deep-structured mapping approach deliberately breaks away from transactional schemas. It consolidates redundant attributes, aligns naming with business language, and models data the way it will be consumed—not the way it was captured. This shift is subtle but essential for long-term success.
Data Types, Formats, and Temporal Consistency Matter
Technical rigor is as important as conceptual clarity. Data types must align across sources to ensure consistent behavior during segmentation and activation. Dates and timestamps, in particular, require careful attention to time zones and formats.
A deep mapping exercise validates these aspects upfront, rather than assuming they will “just work.” Seemingly small inconsistencies here often surface later as inexplicable segmentation results or activation delays.
Mapping Documentation Is Part of the Architecture
Mapping decisions are architectural decisions, and they deserve architectural documentation. Beyond simple field-to-field mappings, teams should capture the reasoning behind choices, including business definitions, source trust levels, and transformation logic.
This documentation becomes critical when identity rules evolve, new sources are added, or teams change. Without it, future changes risk undoing carefully constructed assumptions.
Validate Early With Realistic Data
Theoretical correctness is not enough. A deep mapping practice validates assumptions using real, imperfect data. This includes examining null rates, unexpected value distributions, and edge cases that do not appear in clean test samples.
Early validation exposes structural issues while they are still cheap to fix. Waiting until activation or AI features are layered on top often multiplies the cost of correction.
Design for Evolution, Not Finality
No data model is ever finished. New systems are introduced, regulations change, and business priorities evolve. Deep mapping acknowledges this reality and designs for adaptability.
Loose coupling between sources and unified structures, clear ownership of attributes, and modular mapping strategies all contribute to resilience. Perfection is less valuable than flexibility.
Conclusion
Data mapping in Salesforce Data Cloud is where strategy quietly becomes reality. It translates abstract business intent into concrete structures that power identity resolution, analytics, and engagement.
When approached with depth, discipline, and foresight, data mapping becomes a force multiplier—amplifying every downstream capability. When rushed or treated as a formality, it becomes invisible technical debt.
In Data Cloud, the quality of your outcomes will always reflect the quality of your mappings.


Comments